
Statistics [27]: Unitary Regression Model
Published:
Basics of unitary regression, especially linear regression.
Review: Correlation
Correlation tells us whether the two variables are linearly dependent. If the two variables and
are independent, then
; however, if
, it doesn’t necessarily mean that
and
are independent, there might still be nonlinear relationships between the two variables.
For example, ,
and
are obviously not independent. However,
It doesn’t mean that and
are independent, it only says that
and
are linearly independent.
if and only if
and
are lienarly dependent almost everywhere. That is
Least Square
Suppose the independent variable is and the dependent variable is
. The objective of linear fitting is to find a linear relationship between
and
such that
. Residual is defined as the difference between the actual value and the fitted value, that is
.
Least square is to choose and
to minimize
, that is
Differentiate with respect to
and
respectively, we have
Thus,
Analysis of Variance
where
Therefore,
where
is the total sum of squares (TSS)
is the regression sum of squares (RegSS)
is the residual sum of squares (RSS)
A good fitting has a big RegSS and a small RSS. If TSS = RegSS, the fitting is perfect. The goodness of fit is determined by the coefficient of determination ,
Simple Linear Regression Model
The linear regression model is usually expressed as
where is the error term.
The least square model is an approximation of this linear regression model, where
with
To prove this,
Hence,
With ,
Therefore,
Properties
Least square estimation has the following properties:
(number of parameters subtracted from the freedom, proved in the next post)
are mutually independent (?).
Significance Test
In practice, the lienar regression model is only a hypothesis. Therefore, we need to test the significance of this hypothesis, which is
If is rejected, we can conclude that
and
have a linear relationship; otherwise, it means that there is no significant linear relationship between
and
.
F-Test
When holds,
It can be proved that , which will be proved in the next post.
As , we have,
t-Test
Since
When , we have
When , we have
Hence, confidence interval of and
are respectively
Example
Relationship between the area and price of houses.
| Area (m^2) | Price (10,000) | |
|---|---|---|
| 1 | 55 | 100 |
| 2 | 76 | 130 |
| 3 | 65 | 100 |
| 4 | 156 | 255 |
| 5 | 55 | 82 |
| 6 | 76 | 105 |
| 7 | 89 | 125 |
| 8 | 226 | 360 |
| 9 | 134 | 190 |
| 10 | 156 | 270 |
| 11 | 114 | 180 |
| 12 | 76 | 142 |
| 13 | 164 | 370 |
| 14 | 55 | 115 |
| 15 | 90 | 200 |
| 16 | 81 | 155 |
| 17 | 215 | 516 |
| 18 | 76 | 160 |
| 19 | 66 | 138 |
| 20 | 76 | 170 |
Linear regression using statsmodels.
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import statsmodels.api as sm
data = np.array([[1,2,3,4,5,6,7,8,9,10,11,12,13,14,15,16,17,18,19,20],
[55,76,65,156,55,76,89,226,134,156,114,76,164,55,90,81,215,76,66,76],
[100,130,100,255,82,105,125,360,190,270,180,142,370,115,200,155,516,160,138,170]])
dataDF = pd.DataFrame(np.transpose(data),columns = ['Num','Area','Price'])
Y = dataDF['Price']
X = dataDF['Area']
X = sm.add_constant(X)
model = sm.OLS(Y,X)
results = model.fit()
results.summary()
Results:
OLS Regression Results
==============================================================================
Dep. Variable: Price R-squared: 0.857
Model: OLS Adj. R-squared: 0.849
Method: Least Squares F-statistic: 107.9
Date: Tue, 08 Mar 2022 Prob (F-statistic): 4.94e-09
Time: 12:13:11 Log-Likelihood: -102.61
No. Observations: 20 AIC: 209.2
Df Residuals: 18 BIC: 211.2
Df Model: 1
Covariance Type: nonrobust
==============================================================================
coef std err t P>|t| [0.025 0.975]
------------------------------------------------------------------------------
const -12.8246 22.046 -0.582 0.568 -59.142 33.493
Area 1.9607 0.189 10.390 0.000 1.564 2.357
==============================================================================
Omnibus: 2.958 Durbin-Watson: 0.845
Prob(Omnibus): 0.228 Jarque-Bera (JB): 1.423
Skew: 0.613 Prob(JB): 0.491
Kurtosis: 3.455 Cond. No. 267.
==============================================================================
Warnings:
[1] Standard Errors assume that the covariance matrix of the errors is correctly specified.
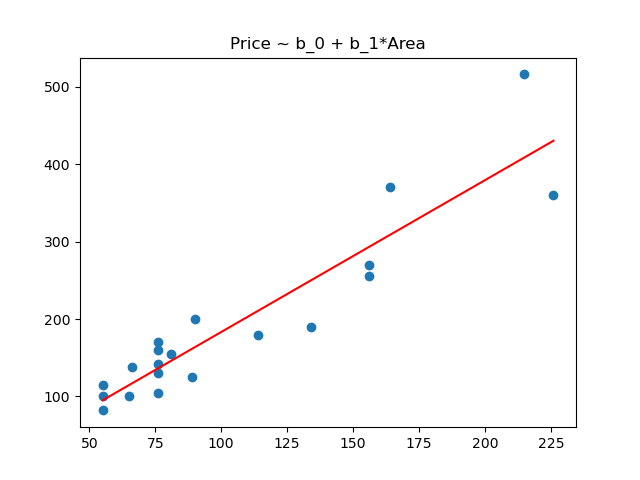
x = [55,76,65,156,55,76,89,226,134,156,114,76,164,55,90,81,215,76,66,76]
x = np.sort(x)
y = results.params[1]*x + results.params[0]
plt.scatter(dataDF['Area'],dataDF['Price'])
plt.plot(x,y,'r')
plt.title('Price ~ b_0 + b_1*Area')
plt.show()
Linear regression using sklearn.
import numpy as np
from sklearn.linear_model import LinearRegression
x = np.array([55,76,65,156,55,76,89,226,134,156,114,76,164,55,90,81,215,76,66,76]).reshape((-1,1))
y = np.array([100,130,100,255,82,105,125,360,190,270,180,142,370,115,200,155,516,160,138,170])
model = LinearRegression(fit_intercept = True).fit(x,y)
Results:
model.coef_
# array([1.96072963])
model.intercept_
# -12.82464801609072
model.score(x,y)
# 0.8570804873379527
Prediction
Suppose , and the regression function is obtained from
. Now fix
such that
, find the predicted value of
along with its confidence interval.
It is easy to verify that is an unbiased estimation with
Consider the distribution of . Firstly,
Hence,
Therefore,
Along with , we have
Denote
,
then the confidence interval of with significance level
is
Nonlinear Least Square
Suppose the joint density function of is
,
exists. Let
, then
Proof. Consider the case of continuous variable,
Hence,
This completes the proof.
The conditional expectation is a random variable dependent on
, and it is the variable closest to
among all the variables that can be expressed by
in the sense of least square.
Table of Contents
- Probability vs Statistics
- Shakespear’s New Poem
- Some Common Discrete Distributions
- Some Common Continuous Distributions
- Statistical Quantities
- Order Statistics
- Multivariate Normal Distributions
- Conditional Distributions and Expectation
- Problem Set [01] - Probabilities
- Parameter Point Estimation
- Evaluation of Point Estimation
- Parameter Interval Estimation
- Problem Set [02] - Parameter Estimation
- Parameter Hypothesis Test
- t Test
- Chi-Squared Test
- Analysis of Variance
- Summary of Statistical Tests
- Python [01] - Data Representation
- Python [02] - t Test & F Test
- Python [03] - Chi-Squared Test
- Experimental Design
- Monte Carlo
- Variance Reducing Techniques
- From Uniform to General Distributions
- Problem Set [03] - Monte Carlo
- Unitary Regression Model
- Multiple Regression Model
- Factor and Principle Component Analysis
- Clustering Analysis
- Summary
Comments